性能优化之代码优化
本文最后更新于:2021/07/05 , 星期一 , 21:32
JS开销和如何缩短解析时间
JS开销
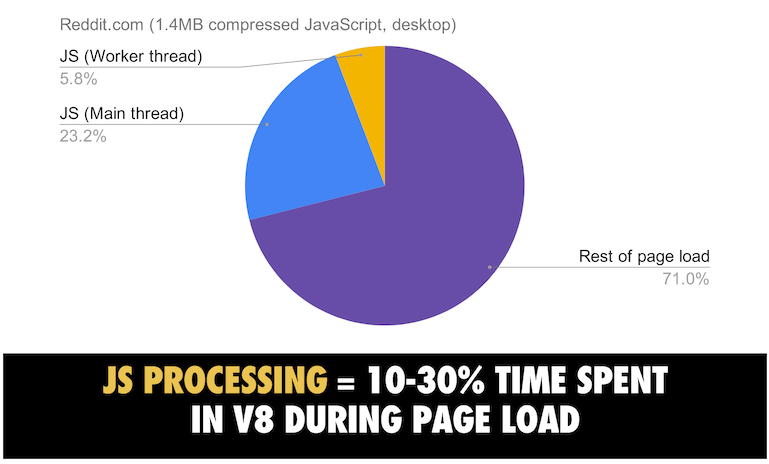
解决方案
网络加载方面:JS文件压缩
编译和解析:代码拆分,按需加载
编译和解析:删除没必要的代码
执行:减少主线程工作量
减少主线程工作量
避免长任务(long task)
避免超过1kB的行间脚本
使用 rAF 和 rIC 进行时间调度
配合 V8 有效优化代码
V8编译原理
生成抽象语法树(AST)和执行上下文:先进行词法分析将源代码拆解成token。在进行语法分析,将token根据语法规则转化为AST。
生成字节码:会根据 AST 生成字节码,并解释执行字节码
执行代码:在执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器就会把该段热点的字节码编译为机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了。经过编译器优化过的代码只能针对某种固定的结构,一旦在执行过程中,对象的结构被动态修改了,那么优化之后的代码会变成无效的代码,这时候优化编译器就需要执行反优化操作,经过反优化的代码,下次执行时就会回退到解释器解释执行。
eg.:
1 | |
查看V8对哪些进行了优化,哪些进行了反优化可以执行node --trace-opt --trace-deopt file.js
V8优化机制
脚本流:下载的过程中对已经下载的足够大的js文件开辟新线程先解析,等都加载完后将全部解析结果合并。
字节码缓存
懒解析(lazy-parsing):主要对于函数而言,先不解析函数内部逻辑,等用的时候在解析。
函数优化
函数的解析方式
懒解析(lazy-parsing):不会创建ast,会创建作用域,但不会在里面包含变量引用或者声明。
饥饿解析(eager-parsing):会建立AST,创建完整的作用域,找出所有语法错误
问题:一个马上要执行的函数在声明的时候会进行一个懒解析,发现是该函数要执行了,又会进行饥饿解析,效率降低。
eg.:
1 | |
问题:使用部分压缩工具(老版本的uglyfy 和 webpack等)时,可能会将上述括号取消掉。
解决:利用Optimize.js优化加载时间。(将括号再加回来)
对象优化
1. 以相同顺序初始化对象成员,避免隐藏类的调整
隐藏类可以理解为“按图索骥”中的图。提高对象属性的访问速度,快速存取对象属性,节省内存空间。
详细可看 V8 中的对象表示 。
文章 JavaScript 引擎基础:Shapes 和 Inline Caches 中详细了隐藏类的相关内容。
1 | |
2. 实例化后避免添加新属性
1 | |
3. 尽量使用Array代替array-like对象
array-like对象:形如函数参数(arguments这种,有索引有length的对象)
1 | |
4. 避免读取超过数组的长度
1 | |
5. 避免元素类型转换
1 | |
避免 -0,除非你需要在代码中明确区分 -0 和 +0。
同样还有 NaN 和 Infinity。它们被表示为双精度,因此添加一个 NaN 或 Infinity 会将 SMI_ELEMENTS 转换为DOUBLE_ELEMENTS。
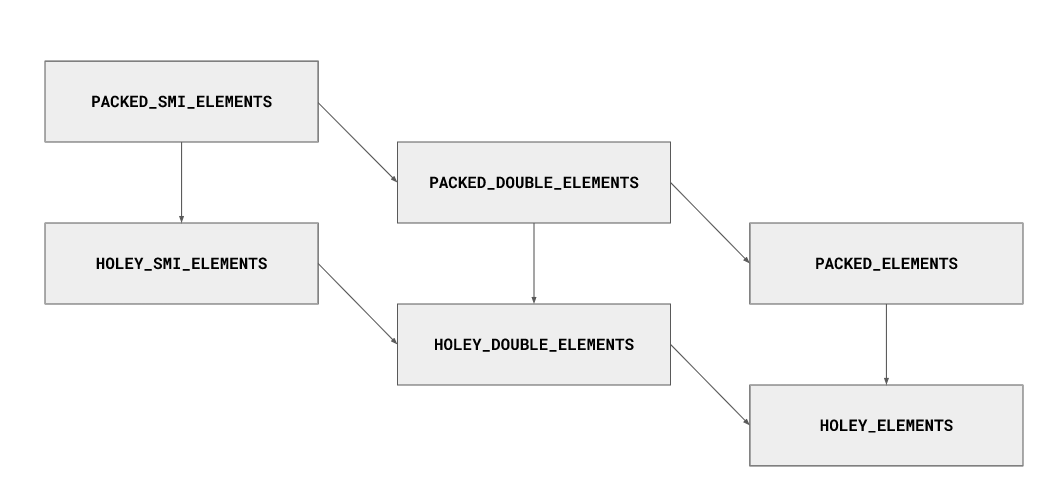
只能通过格子向下过渡。一旦将单精度浮点数添加到 Smi 数组中,即使稍后用 Smi 覆盖浮点数,它也会被标记为 DOUBLE。类似地,一旦在数组中创建了一个洞,它将被永久标记为有洞 HOLEY,即使稍后填充它也是如此。
越具体优化越多,越通用优化越小。
详细可见你可能不知道的V8数组优化
6. 避免创建洞
1 | |
解决方案
1 | |
7. 避免多态
如果代码需要处理包含多种不同元素类型的数组,则可能会比单个元素类型数组要慢,因为代码要对不同类型的数组元素进行多态操作。
1 | |
调用了each3次,并且每次都没有给它相同的元素类型,在V8中,它采用内联缓存(Inline Caches,简称 IC)来缓存调用的实现以优化这些操作的执行过程。
当第一次只传入类型为packed_smi_element的[1,2,3],v8会使用IC来缓存这个方法的调用,记录元素类型以及其他信息,那么下一次传入packed_smi_element时,直接就可以从缓存里取到优化后的调用方法,然后进行调用。
但是第二次如果传入的不一样的元素类型,比如packed_double_number,那么v8又会重新缓存一个新的调用实现(适用于packed_double_number),那么传入元素的时候就需要进行2次判断了,先判断是不是smi,如果不是,就判断是不是packed_double_number,如果是其他,那么又会重新缓存一个新的调用实现.优化与反优化
HTML优化
减少iframes使用。必要使用时,先建立个空iframe,延迟或在合适的时机使用
setAttribute赋值src压缩空白符
避免节点深层级嵌套
避免table布局
删除注释(和压缩空白符一个道理,压缩文件)
CSS&JavaSCript尽量外链(避免HTML大文件)
标签语义化(1.方便人看懂代码 2.方便浏览器针对标签做的优化)
JS文件放到尾部(加载JS是阻塞的,会阻塞渲染)
CSS对性能的影响
利用DevTools测量样式开销
CSS优化
降低CSS对渲染的阻塞(1.尽量早的去下载CSS 2.降低CSS文件大小,仅加载首屏需要的CSS,不需要的延迟加载)
利用GPU进行完成动画(单独出一个层,不影响布局与绘制)
使用contain属性(减少重绘与回流)
使用font-display属性(让文字更早的显示在页面上,减轻字体闪动)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!